
Introduction
Ensuring safety in autonomous driving requires scalable generation of realistic, controllable driving scenes beyond what real-world testing provides. Yet existing instruction guided image editors, trained on object-centric or artistic data, struggle with dense, safety-critical driving layouts. We propose HorizonWeaver, which tackles three fundamental challenges in driving scene editing: (1) multi-level granularity, requiring coherent object- and scene-level edits in dense environments; (2) rich high-level semantics, preserving diverse objects while following detailed instructions; and (3) ubiquitous domain shifts, handling changes in climate, layout, and traffic across unseen environments. The core of HorizonWeaver is a set of complementary contributions across data, model, and training: (1) Data: Large-scale dataset generation, where we build a paired real/synthetic dataset from Boreas, nuScenes, and Argoverse2 to improve generalization; (2) Model: Language-Guided Masks for fine-grained editing, where semantics-enriched masks and prompts enable precise, language-guided edits; and (3) Training: Content preservation and instruction alignment, where joint losses enforce scene consistency and instruction fidelity. Together, HorizonWeaver provides a scalable framework for photorealistic, instruction-driven editing of complex driving scenes, collecting 255K images across 13 editing categories and outperforming prior methods in L1, CLIP, and DINO metrics, achieving +46.4% user preference and improving BEV segmentation IoU by +33%.
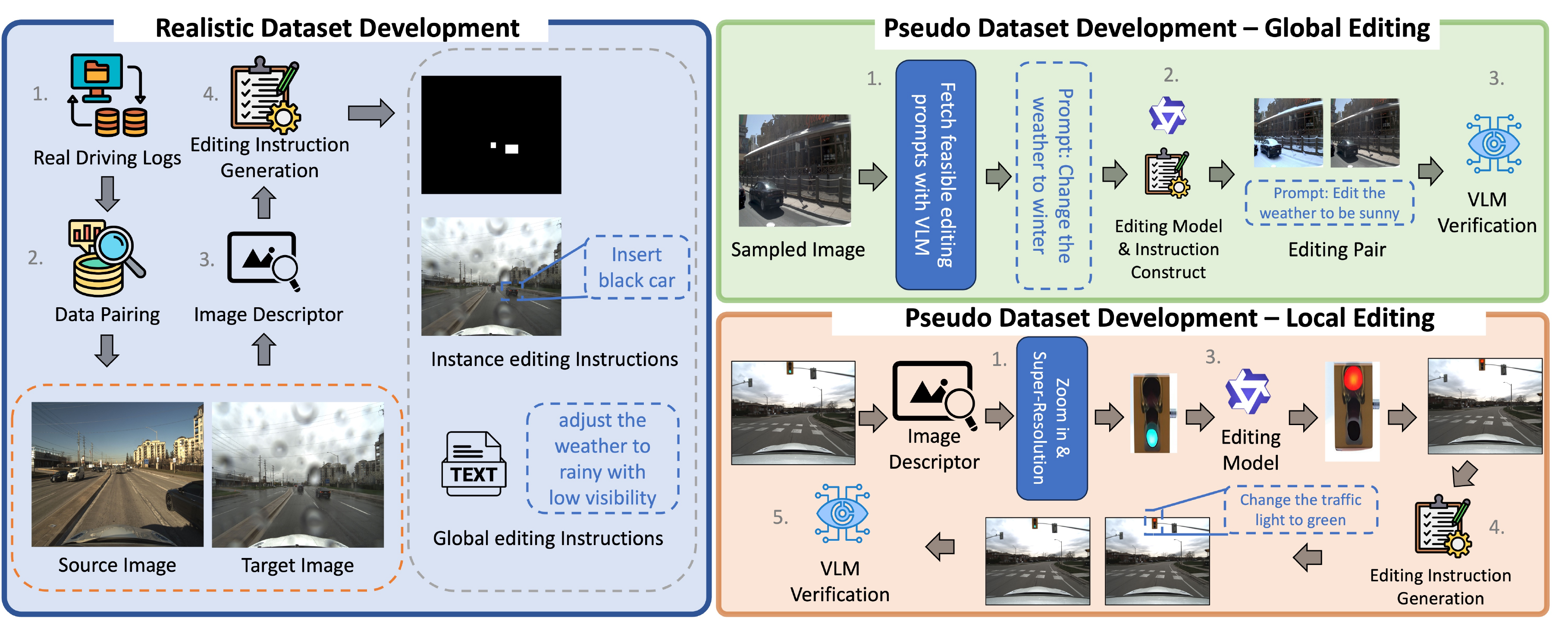
Figure: Overview of our Dataset generation framework. Real-world data (blue) are paired by camera pose and annotated using an image descriptor pipeline and passed to an LLM to produce instructions. Pseudo-data (orange) for local edits crop an annotated object before VLM filtering; global edits (green) apply VLM filtering to full images. Our dataset is composed of image pairs, global editing instructions, and masks indicating fine-grained edits to perform.
Language Guided Masks
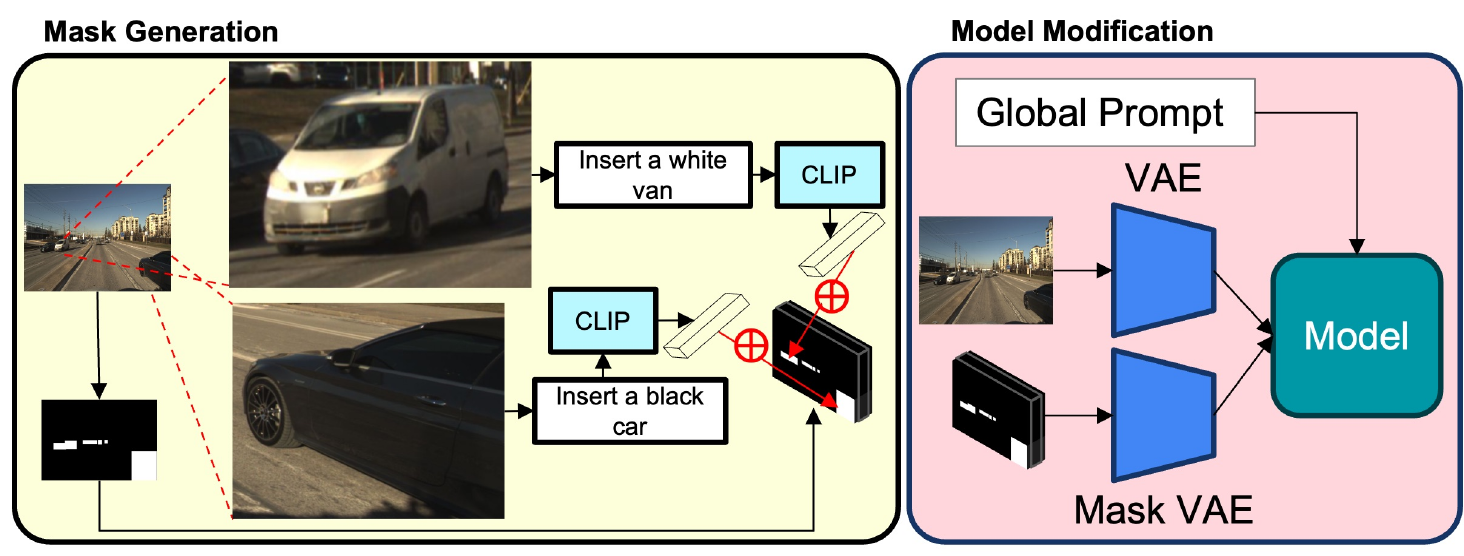
LangMask Generation and Training: Left: To provide fine-grained instructions with rich semantics, we insert CLIP text features into binary masks. Right: To support LangMasks, we copy and expand the VAE. It is trained end to end with the editing model.
Training Language-Guided Image Editing
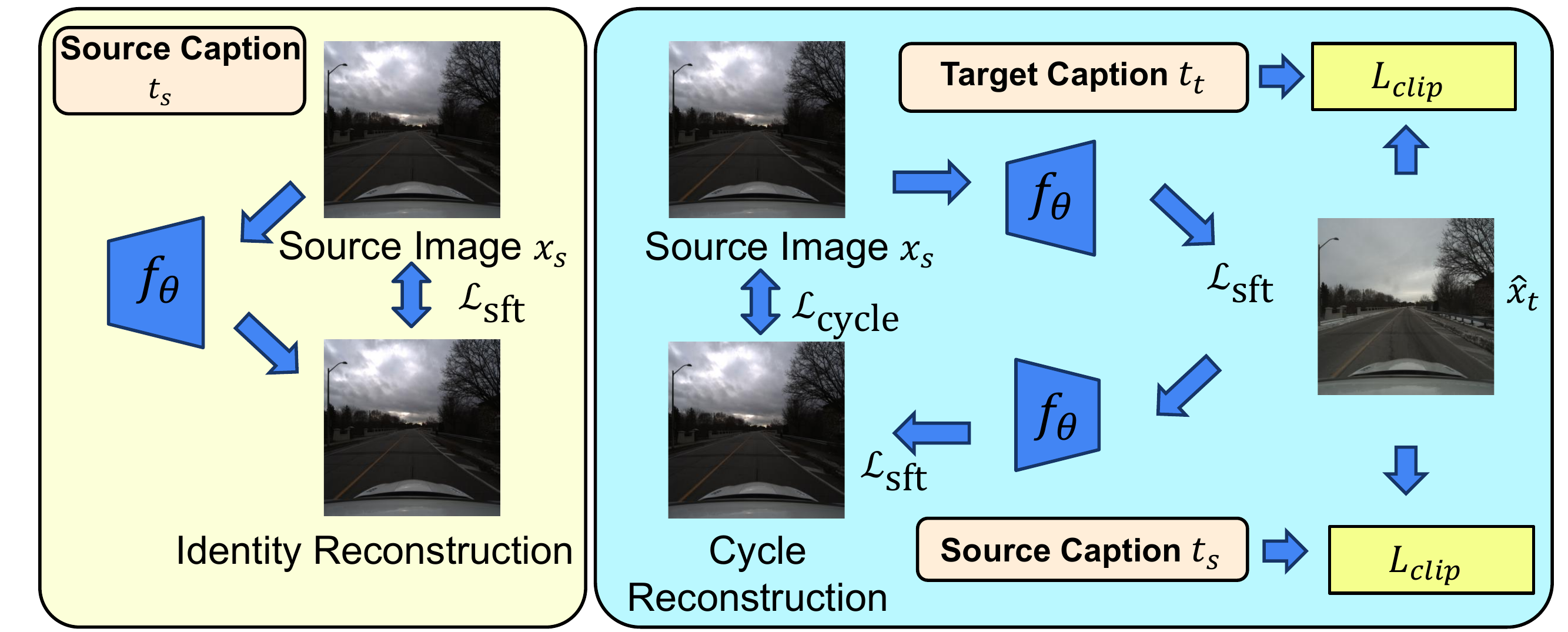
Training language-guided driving scene image editing: Our training pipeline supports both supervised training for paired images and unsupervised training for unpaired ones (e.g. downstream unseen real scenarios). We include three training objectives: supervised fine-tuning, cycle consistency, and CLIP loss.
Results






Citation
@inproceedings{soroco2025horizonweaver,
title={HorizonWeaver: Generalizable Multi-Level Semantic Editing for Driving Scenes},
author={Soroco, Mauricio and Pittaluga, Francesco and Tasneem, Zaid and Aich, Abhishek and Zhuang, Bingving and Chen, Wuyang and Chandraker, Manmohan and Jiang, Ziyu},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}
year={2026},
organization = {IEEE/CVF}
}